This article is part of the Production Automation Foundations series.
Automation is not new to most operations teams reading this. You already have scripts, pipelines, health checks, and scheduled jobs keeping your environments running.
And yet, automation still gets blamed when things go sideways.
Usually not because automation itself failed — but because it was asked to operate outside well-understood boundaries.
In real production systems (especially hybrid and legacy-heavy ones), automation works best when it stays in constrained, predictable spaces. The most reliable automation doesn’t try to run everything. It quietly handles narrow problems over and over, with minimal risk.
This article focuses on those areas — the places where automation consistently delivers value without increasing operational fragility.
Not theory. Patterns.
Automation for Detection vs Execution
One of the most important distinctions in production is automation that detects versus automation that acts.
Detection automation answers questions:
- Is this service healthy?
- Did this deployment introduce errors?
- Has disk usage crossed a threshold?
- Did configuration drift from baseline?
Execution automation changes things:
- Restarting services
- Scaling infrastructure
- Applying configuration changes
- Failing over traffic
- Rolling back releases
Detection is almost always safer.
Execution carries risk.
Where detection automation shines
Detection automation scales extremely well because it:
- Is observational, not destructive
- Produces signals instead of side effects
- Supports human decision-making
- Can be refined without impacting production behavior
In mature environments, detection automation usually covers:
- Service health checks
- SLO error budget tracking
- Log anomaly detection
- Resource saturation alerts
- Config drift reports
- Backup validation
These systems don’t fix problems directly. They shorten time-to-awareness.
That alone is enormous operational leverage.
Teams that invest heavily in detection often discover they need less aggressive execution automation because engineers see issues earlier and intervene more effectively.
Where execution automation belongs
Execution automation works best when:
- The action is routine
- The blast radius is small
- The outcome is predictable
- Rollback is easy
Examples from real environments:
- Restarting a stateless worker pod
- Clearing a stuck message queue consumer
- Rotating application logs
- Replacing a failed VM in an autoscaling group
- Re-running a failed batch job
Notice the pattern: localized, repeatable actions with well-understood effects.
What tends to fail is broad control automation:
- “Auto-remediate any alert”
- “Self-healing everything”
- “Fully autonomous incident response”
Those systems usually lack enough context to act safely across diverse production states.
Detection first. Targeted execution second.
Reversible vs Irreversible Automation
A practical way to evaluate automation risk is to ask:
Can we easily undo this?
Reversible automation (low risk)
Good candidates include:
- Restarting processes
- Re-running idempotent jobs
- Reapplying known-good configuration
- Rolling back deployments
- Scaling stateless services
These actions can usually be reversed or repeated safely.
They’re excellent automation targets.
Teams often automate these early because failure modes are obvious and recovery paths are clear.
Irreversible automation (high risk)
This includes:
- Data deletion
- Schema migrations
- Certificate revocation
- Access removal
- Production traffic re-routing
- Infrastructure teardown
These actions change state in ways that are expensive or impossible to undo.
They don’t mean “never automate” — but they demand:
- Explicit human approval
- Strong validation
- Limited scope
- Clear audit trails
In practice, many high-performing teams keep irreversible actions semi-manual on purpose. They automate preparation and verification, but not final execution.
That boundary preserves safety.
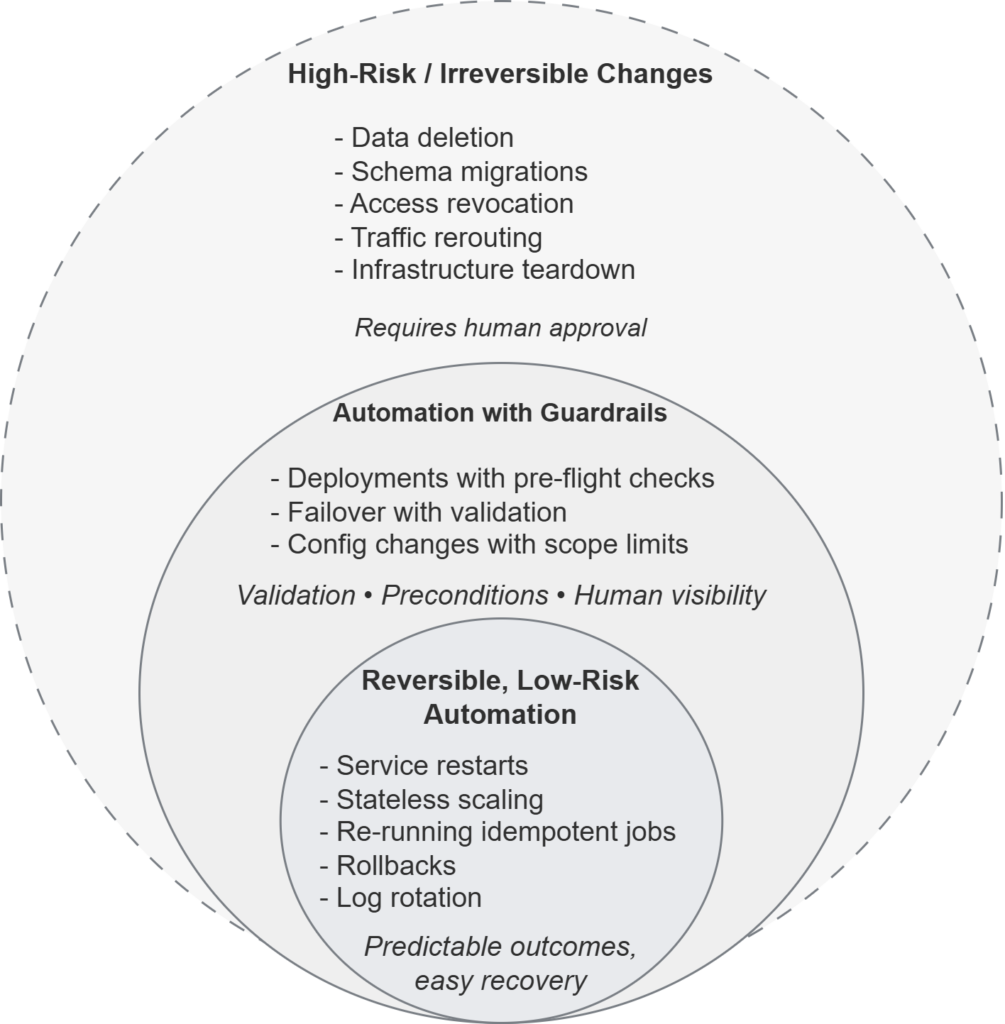
A conceptual model showing where automation works reliably.
Low-risk, reversible actions sit at the core. More complex operations require guardrails and validation. High-impact or irreversible changes remain human-controlled. Effective automation grows inward from safe boundaries rather than outward toward full autonomy.
Guardrails, Validation, and Pre-Flight Checks
Automation that works in production almost always has guardrails.
Not optional ones. Mandatory ones.
Before making changes, reliable systems typically verify:
- Current state matches expectations
- Target systems are reachable
- Dependencies are healthy
- Inputs are valid
- Impacted resources are within scope
This looks like:
- Confirming a host belongs to the intended environment
- Checking that a service is already degraded before restarting
- Verifying a deployment artifact exists before rollout
- Ensuring database replicas are caught up before failover
These checks slow automation down slightly.
They dramatically reduce accidental damage.
Pre-flight checks beat post-mortems
Many outages attributed to “automation failures” are really missing validation failures.
The automation did exactly what it was told — just without confirming it should.
Experienced teams treat guardrails as first-class features, not defensive afterthoughts.
If automation can’t validate its assumptions, it shouldn’t proceed.
Reporting, Drift Detection, and Change Visibility
Some of the most valuable automation in production doesn’t touch systems at all.
It watches.
Drift detection
Environments drift. Always.
Configuration changes, packages update, permissions shift, and manual fixes sneak in during incidents.
Automation that continuously reports drift provides:
- Early warning of configuration divergence
- Visibility into undocumented changes
- Evidence for post-incident reviews
- Confidence in baseline integrity
This is especially powerful in hybrid environments where not everything is centrally managed.
Drift detection rarely causes outages. It simply surfaces reality.
Change visibility
Another quiet success pattern: automated change reporting.
Examples:
- Daily summaries of infrastructure changes
- Deployment timelines correlated with error rates
- Access modifications logged centrally
- Certificate expiration dashboards
These don’t prevent incidents directly.
They make incidents understandable.
Teams that invest here recover faster because they can answer:
- What changed?
- When?
- Where?
That’s operational gold.
How Teams Choose Safe Automation Boundaries
Across many production environments, similar decision patterns emerge.
Teams tend to automate when — a decision space explored further in What to Automate — and What to Leave Manual (For Now):
- The task is frequent
- The outcome is predictable
- The blast radius is constrained
- Recovery is straightforward
- The behavior is well documented
They hesitate when:
- State is ambiguous
- Dependencies are complex
- Impact is wide
- Rollback is unclear
- Context matters
This isn’t fear — it’s experience.
Automation works best when it’s boring.
The goal isn’t autonomy. It’s repeatability.
Why Starting Small Outperforms Broad Automation
Broad automation promises coverage.
Small automation delivers reliability.
Teams that succeed usually:
- Start with detection
- Add reversible execution
- Build guardrails early
- Expand scope slowly
- Keep humans in the loop for high-impact actions
They don’t treat automation as a maturity ladder.
They treat it as a set of carefully placed levers.
Each lever solves a specific operational problem.
Over time, those small improvements compound.
Not because automation became smarter — but because boundaries stayed clear.
Quiet Success Looks Like This
Healthy production automation rarely makes headlines.
It looks like:
- Alerts that arrive early
- Rollbacks that just work
- Drift that gets noticed before incidents
- Routine failures that resolve automatically
- Engineers who trust their systems because they understand them
That’s not glamorous.
It’s stable.
And stability comes from limits, not ambition.
Related reading
- What to Automate — and What to Leave Manual (For Now) — how to decide where automation belongs and where it introduces risk
- Why Automation Often Reduces Reliability Before It Improves It — how automation amplifies failure modes when boundaries are unclear